“Creating Awesomely reliable networks”
Do you ever ask why in a world where often we cant perform our jobs successfully without IT, there are so many failures and you need a support contract just to keep things working?
At Andisa, we asked! We approached our clients, we quizzed our engineers and more importantly we interrogated our ticketing system (ACL or Andisa Call Logger).
The founder of the leading business development organisation – WhatIf Forums explained that the cost of IT outages for a £1M turnover business is approximately £1100 per hour!
Often the cost is attributed to the cost of an engineer but the true cost is that to your business, lost sales, lost ability too ship / invoice and problems responding to customers! This doesn’t counter for the emotional cost from the stress!
It quickly became apparent that the answer to the question is in the numbers. It was possible to identify key issues and then focus on them until they were resolved.
The key issues were things like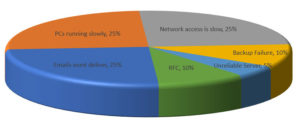 an unreliable network, not having software updates applied, having adequate PCs and servers for the task, in-secure Wi-Fi.
an unreliable network, not having software updates applied, having adequate PCs and servers for the task, in-secure Wi-Fi.
When we explored the statistics, the main challenges were easy to understand:
- 25% – Emails that wouldn’t deliver
- 25% – Pcs that are slow or inadequate
- 25% – Network running slowly
- 10% – Backup not passing
- 5% – Why is the server unreliable / Wont start-up / Reboots on its own.
- The remaining 10% were requests for change – new user setup, new printers, etc
We decided that it must be possible to have Zero Call outs if we could work with our clients closely. But it needed partnership. Not just hard graft. We needed to understand our clients deeply and work out what was critical to each.
We started by identifying tools that would help bring issues to the foreground and then give us sufficient information that the issues could be eliminated.
Automatic Monitoring.
This is key to the whole challenge. Monitoring means that its possible to measure effects and then focus on the negative points so that they can be removed. We chose to implement PRTG automatic monitoring. It is an industry standard system that can interface to most devices. The authors constantly add extra features.
In our environment it serves two main functions:
- Early warning system.
The system gives a traffic light view for a network. When it goes read there is about to be a problem. We can react before the system becomes critical. Support resources are less stressed and your business is more productive.
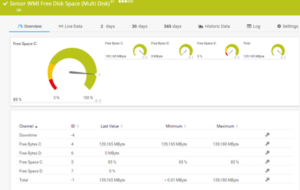
- Generate the numbers.
PRTG records the key status of a network and keeps the information for many months. Automatic We can review the information and use it to help perform capacity and reliability management.
In real time, for example, we are able to see just how much disk space is in use on your server. We can deduce whether data growth is caused by clumsiness (sudden increases as users duplicate data) or by real need ( a steady climb as data grows).
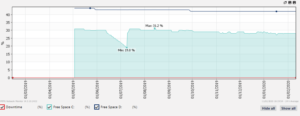
that Problems are detectable with proper monitoring. Most servers now have remote monitoring and control built in.
We can power cycle servers, see physical faults and monitor the hardware remotely.
We added PRTG (an automated monitoring system) for all of our client systems that are under contract. The system predicts hardware failure by measuring speed of disks, key temperatures etc and sends email alerts out to us. We can dispatch an engineer in a planned way that doesn’t affect business. By spotting the problem sooner, we avoid data loss from faulty hardware.
Planning for upgrade.
Most business owners understand that new tools work better and staff work harder when they are given one. However how do you choose which part of a network should be replaced without wasting money?
The answer is to design a rolling replacement scheme based on the numbers. Work out how well each PC performs and also map out what software is needed for your staff. Then poorly performing PCs can be replaced whilst higher specification machines can be better utilised.
We had already developed a tool to audit every PC easily. The reports give several outputs including:
- A list of software in use including the total license count.
- A performance score for each PC out of 10.
We had used the tool to list software and PCs so that a network could be secured. However the reports also mean it is easy, based on metrics, to generate the information needed to plan the rolling replacement of a network in cost effective way.
Over the last 24 months we have repeatedly run the audit for our contract clients and then met with them to discuss what needs replacing in the coming months. The approach avoids sudden and large overspend by enabling planning and better budget control.
Better Configurations
 After searching issue logs and correlating against actual usage recorded on PRTG, it soon became apparent that problems were arising because a small number of users were abusing the networks. It was a common cause across several networks.
After searching issue logs and correlating against actual usage recorded on PRTG, it soon became apparent that problems were arising because a small number of users were abusing the networks. It was a common cause across several networks.
Most of the time this was legitimate network traffic that could swamp the core of a clients network. Some of the time it was caused by social media or streaming traffic. Staff just were not aware of their affect on others.
We added bandwidth control or “quality of service” settings to the networks in question and this overcame the issues with almost zero cost. The next step was to add VLAN technology (where networks are separated logically without adding extra cables) to the systems we managed. This phase has taken longer because not all client equipment were able to handle the configuration. Some had to be upgraded. However once working, the enhanced security and cloud based management made it possible for us to identify even which PC was causing a problem and then quickly take steps to manage the issue.
VLAN configurations also let you create a public network and a staff network that share a common internet connection without compromising security.
Finally we added web site filtering and control. This helped control social media by setting times of the day, or areas of a building where access was granted, but preventing unwanted use from affecting the cre network.
This may seem overkill for an SME business but in truth even home users benefit from proper network management. It avoids problems, reduces frustration and makes the whole experience better.
Cloud Backups
![]() On site backups rely on staff to change disks and holiday periods invariably cause problems. Cloud backups work far more efficiently because they don’t rely on a person to get start the process, or to take data off site. The risk is that somebody will make a change to where data is stored and the automatic system wont be updated.
On site backups rely on staff to change disks and holiday periods invariably cause problems. Cloud backups work far more efficiently because they don’t rely on a person to get start the process, or to take data off site. The risk is that somebody will make a change to where data is stored and the automatic system wont be updated.
Our systems did previously all “email home” to warn us if there was a failure. When we reviewed the information we spotted that almost every bank holiday backups would become unreliable and the work to get them back into order was significant. It was simple issues – the wrong disk inserted or worse, not connected.
We chose to use a leading Backup system called Storegrid and then to host it on servers in our own data centre. This gives us full control of the system and avoids cost from the constant data growth associated with backups. Once our clients migrated into the system backups became reliable. Now we spend our time performing test restores rather than nursing the ongoing process.
This means we can make sure that recovery time is understood. If the time for a full recovery is too long then we can help plan alternatives.
![]() Emails were next on the horizon. Our client facing mail servers already had filter and spool technology in place, so that if your internet connection is off, inbound mail still arrives.
Emails were next on the horizon. Our client facing mail servers already had filter and spool technology in place, so that if your internet connection is off, inbound mail still arrives.
We redeveloped the systems so that outbound mail was managed carefully. The servers prevent you from becoming blacklisted by slowing down delivery when you send a mail to a large number of recipients, or if your business sends mail suddenly.
Update Management
Windows updates are becoming more and more necessary to ensure reliability and security of your system. However the download of every update for every PC causes significant load. We configured the routers we maintain to control the bandwidth and where ever possible we added WSUS servers so that one download could be used across all of the devices.
Our engineers volunteers to schedule when the reboots would take place and this put the updates in control.
The outcome is that reboots happen at convenient times. Clients don’t have unexpected reboots and our support team are in control of their own schedules.
The outcome is “Zero Callout” managed IT support.
The approach of IT by numbers has made Zero Callout possible! A combination of approaches – getting the metrics are right, accurate ticket logging & regular reviews, adding monitoring, planned replacement schemes, proper network configuration and planned management of services has made it a reality.
In 207 we decided that we could help clients more. In Nov 2019 we started monitoring the number of times we called out to clients and by January 2020 we had zero callouts for 4 weeks. That means that the steps we put in place have avoided the need to rush out with a screwdriver. The maintenance work still gets done but its performed in a proactive managed way that means our clients can work happily during the day with no breakages on the IT front.
Why did we challenge the accepted norm? Because now our clients systems are more reliable. Our clients can be more productive. At the same time we have managed to reduce cost of support and reduce increaes to the cost of living! Our consultants feel they are giving better service and are proud.
More importantly we have more time for meeting with clients to plan for the future and to run projects.
Thankyou to our key clients who took part in this project with us.
The entire team that handles our tickets at Andisa are all super friendly, professional, knowledgeable and an absolute pleasure to work with.
Most recently Ash has been setting up some laptops with some fairly obtuse software for us, however, the process, which is usually difficult and arduous, has been really smooth thanks to him.
I look forward to working with him again!